A Lingüística de Corpus
e a sala de aula de língua estrangeira:
interfaces
Tania Shepherd (UERJ)
Vander Viana (PUC-Rio)
Introdução
O presente trabalho investiga o uso de agrupamentos lexicais por aprendizes de inglês como língua estrangeira (doravante ILE) de nível avançado, oriundos de cursos livres na cidade do Rio de Janeiro. O estudo é um encaminhamento de Viana (2005).
Aqui parte-se de Sinclair (1991), que entende todo e qualquer texto, oral ou escrito, como o resultado da combinação de dois princípios: o princípio da livre escolha (open-choice principle)[1] e o princípio idiomático (idiom principle). O primeiro rege escolhas livres de itens lexicais para a formação do discurso; o segundo lança mão de um repertório pré-existente de combinações lexicais.
Este trabalho baseia-se em Altenberg (1993), que afirma que o princípio predominante na produção de aprendizes de línguas estrangeiras é o princípio idiomático. Baseia-se igualmente nos inúmeros estudos a respeito do inglês produzido por falantes de línguas européias que não o português (cf. Aijmer, 2002; Housen, 2002; Ringbom, 1998), que atestam o uso inadequado do princípio idiomático. Os aprendizes usam expressões, mas ora as usam em excesso, ora em número insuficiente, ora em combinações que não são permitidas pela gramática.
A presente pesquisa se alinha a inúmeros outros trabalhos, como os de Sinclair (1991), Cowie (1998) e Scott e Tribble (2006), que investigaram freqüência e distribuição de agrupamentos de palavras em determinados tipos texto. Para tal, utiliza-se aqui o conceito de ‘feixes lexicais’ (cf. Biber; Conrad; Cortes, 2004), ou seja, grupos de palavras gerados por programas de computador com base em repetição e distribuição sistemáticas em corpora específicos.
Segundo Scott e Tribble (2006: 131), um agrupamento[2] lexical nada mais é do que um produto artificial oriundo de programas extratores. Na verdade, segundo esses autores, o agrupamento lexical existe com base em critérios puramente distributivos, ou seja, dada uma combinação de dois, três ou quatro itens lexicais, se essa combinação ocorrer em um número mínimo de vezes dentro de um texto ou coletânea de textos, ela configurará um ‘agrupamento’ ou ‘feixe lexical’. Entretanto, os mesmos autores afirmam (Scott; Tribble, 2006: 132) que um exame cuidadoso de uma lista de agrupamentos lexicais pode ajudar a entender como os textos de usuários experientes são formados e em que nível as performances de aprendizes coincidem ou se diferenciam deles.
Este artigo começa apresentando um breve perfil dos estudos sobre escrita em ILE a partir de corpora digitalizados. Em seguida. discute o que são feixes lexicais, para depois descrever como essa unidade é aplicada no tratamento dos dados. Por fim, apresenta conclusões parciais e possíveis encaminhamentos para a pesquisa.
Pesquisa sobre escrita em ILE
Uma das mais significativas inovações na pesquisa sobre a aquisição da escrita em língua estrangeira e em especial em ILE, surgiu, por volta da década de noventa, com a possibilidade de formação de grandes corpora digitalizados compostos de escrita de aprendizes em vários níveis de performance (Hyland, 2002: 176). Esses corpora fornecem evidência dos recursos lexicais, gramaticais e discursivos utilizados por aprendizes na aquisição da escrita. Além disso, mostram os itens que são usados freqüentemente por determinados grupos de aprendizes, os que são usados em excesso (overuse) e os que são pouco ou nada usados (underuse).
Esse novo campo de investigação da Lingüística Aplicada, chamado em inglês de Computerized Learner Corpora (doravante CLC), tem seu ancestral na antiga Análise de Erros. Entretanto, os corpora da Análise de Erros não serviam para ilustrar nada além dos erros propriamente ditos, o que tornava a Análise de Erros uma área altamente prescritiva. Além disso, outra diferença vital é que uma vez identificados os ‘erros’, e analisados fora de seus contextos originais (cf. Granger, 1998a: 6), os corpora da Análise de Erros não eram reaproveitados.
O que acontece hoje dentro da área de CLC é que o mesmo corpus, compilado e armazenado sob critérios corretos, pode ser ponto de partida para análise do perfil de linguagem utilizado por grupos de aprendizes, dando acesso não só aos seus ‘erros’, mas principalmente à sua interlíngua. Além disso, os corpora de aprendiz também oferecem como vantagem um potencial de integração entre a pesquisa e a prática. Como diz Leech (1998: xiv),
Suponhamos que uma professora X, em um país que não tenha inglês como primeira língua, ensine inglês a seus alunos todas as semanas, e de vez em quando lhes peça para escrever composições ou outros trabalhos naquela língua. Ora, ao invés de devolver os trabalhos aos alunos com comentários e um suspiro de alívio, ela guarde as composições em seu computador e construa, gradualmente, semana após semana, uma coletânea maior e mais representativa dos trabalhos de seus alunos. Ajudada por ferramentas computacionais como um concordanciador[3], ela poderá extrair dados e informações sobre as freqüências lexicais desse ‘corpus’ e poderá analisar o progresso de seus alunos enquanto grupo, com alguma profundidade. As questões de pesquisa que se abrem são mais significativas quando se compila um corpus.[4]
Portanto, trabalhar com CLC significa partir de dados empíricos e não de universais lingüísticos idealizados, para chegar aos vários estágios da interlíngua de qualquer grupo de aprendizes.
Feixes lexicais: estrutura e função
Em língua inglesa, a investigação de agrupamentos lexicais, que vão desde expressões pré-fabricadas até conjuntos aleatórios determinados tão somente por distribuição e freqüência, conta com bibliografia extensa (cf. Stubbs, 2001). O presente trabalho optou pelo aporte teórico de Biber, Conrad e Cortes (2004), que fornece critérios para extração de feixes lexicais a partir de corpora formados de tipos de texto distintos (ou registros, rótulo adotado pelos autores) e classificação em termos de função e estrutura. Como dizem Scott e Tribble (2006: 131), os feixes “fornecem meios alternativos de se diferenciar entre textos pertencentes a diferentes corpora”[5].
Em termos estruturais, o estudo de Biber, Conrad e Cortes (2004) constatou, a tendência de usuários experiente de língua inglesa repetirem agrupamentos contendo sintagmas verbais simples (tipo 1), orações subordinadas (tipo 2), e sintagmas nominais / preposicionais (tipo 3), que variavam em número e distribuição de acordo com o registro. Considerando os feixes encontrados sob outra perspectiva, Biber, Conrad e Cortes (2004) verificaram a existência de determinadas funções ou papéis de acordo com o registro: havia feixes que atuavam como marcadores de posicionamento, de referência e de organizadores do discurso.
Através dos variados perfis de freqüência e distribuição encontrados lexicais, tanto em termos de estrutura como de função desempenhada, os autores traçaram o perfil de cada um dos diferentes registros que compunham os corpora investigados.
Metodologia
Para a presente pesquisa, compilou-se um corpus de estudo formado de redações em língua inglesa, que eram parte integrante de testes ou provas de três cursos livres em seis localidades da cidade do Rio de Janeiro. A coleta foi feita nos dois últimos níveis de cada curso livre, incluindo-se também a modalidade de formação de professores. Em um dos cursos, no entanto, também foram coletados trabalhos oriundos de um programa específico de ensino de técnicas de redação.
Os temas dos trabalhos foram decididos pelo professor de classe ou foram ditados pelo material didático utilizado. As composições contêm aproximadamente 250 palavras, sendo que nenhuma redação foi editada, a não ser pela exclusão dos títulos que, em sua grande maioria, foram fornecidos pelos próprios professores. Cada aluno só contribuiu com uma única redação. Após a coleta, todas as composições foram digitadas. Nenhum erro foi corrigido, , com exceção dos erros ortográficos.
O corpus de pesquisa, caracterizado como pequeno, (Berber Sardinha, 2004: 26).contém 105 redações, com 30.301 palavras no total e 2.870 palavras diferentes. O programa utilizado para levantamento dos feixes lexicais foi WordSmith Tools (Scott, 1999), mais especificamente a ferramenta WordList . No caso do presente estudo, foram acatadas as razões de Biber, Conrad e Cortes (2004: 376) em favor de quatro para o número de itens dos feixes lexicais. A opção por quatro palavras é bem argumentada por Biber et al. (2000: 992):
Os feixes de três palavras podem ser considerados como uma espécie de associação mais extensa de colocados e, desta forma, são extremamente comuns. Feixes de quatro, cinco ou seis palavras têm uma natureza mais frasal mas, por outro lado são menos comuns[6].
Além de conterem quatro palavras, cada feixe teria que aparecer em pelo menos duas composições distintas em número igual ou superior a três vezes. Entretanto, nem todas as seqüências de quatro palavras geradas pelo computador sob essas condições foram usadas na análise, somente aquelas que marcavam o início de um sintagma. Desta forma, foram excluídas seqüências tais como ‘be reduced to the’, ‘best things in life’ e ‘order to have a’, e deixadas as seqüências ‘should be reduced to’, ‘the best things in’ e ‘in order to have’, que marcam o início de sintagmas verbal, nominal e preposicional.
Análise de dados
Em termos estruturais, ocorreram feixes do tipo 1, que englobam fragmentos de sintagmas verbais, começando com o sintagma verbal propriamente dito (‘have a lot of’), precedidos por um pronome (‘he or she is’ / ‘we live in a’) ou contendo um sintagma verbal na voz passiva (‘should be reduced to’).
Observaram-se seqüências de estruturas do tipo 2, ou seja, aquelas constituídas de fragmentos de orações subordinadas, contendo pronome, verbo e início da oração dependente (‘I hope to be’), iniciando-se com um verbo no infinitivo (‘to have a good’), ou por ‘if’ (‘if you are a’) ou ‘when’ (‘when I got to’).
Quanto ao tipo 3, os exemplos extraídos indicam que os feixes podem começar com o sintagma nominal propriamente dito (‘a lot of money’) ou o sintagma preposicional (‘between money and happiness’); podem ter um sintagma nominal sendo pós-modificado por ‘of’ (‘the end of the’), ou podem conter um sintagma nominal seguido por um sintagma preposicional (‘the best things in’). Na Figura 1, são apresentados alguns exemplos para melhor visualização das instâncias de análise.
|
Tipo 1 |
Tipo 2 |
Tipo 3 |
|
have a lot of |
I hope to be |
a lot of money |
|
he or she is |
to have a good |
between money and happiness |
|
we live in a |
if you are a |
the end of the |
|
should be reduced to |
when I got to |
the best things in |
Figura 1: Classificação estrutural de feixes lexicais
Quanto à função, há no corpus feixes de posicionamento, ou seja feixes que indicam a atitude do escritor em termos de seu grau de certeza / incerteza (‘believe in Santa Claus’), seus desejos e vontades (‘I hope to be’), suas obrigações / diretivas pessoais (‘they have to be’) e impessoais (‘should be reduced to’), suas intenções / predições (‘I will be working’), e suas habilidade (‘we can say that’).
Um outro papel funcional dos feixes lexicais, também identificado por Biber, Conrad e Cortes (2004), é o de organizar o discurso, podendo ocorrer de duas formas distintas. Há feixes que são responsáveis pela introdução de tópicos como é o caso de ‘if you are a’ e outros que melhor elaboram ou clarificam o discurso como, por exemplo, ‘on the other hand’.
Finalmente, os feixes também podem ter uma função referencial. Eles podem identificar ou focalizar um determinado assunto ou processo (‘is the one that’), especificar quantidade (‘a lot of money’), nomear atributos ou qualidades tangíveis (‘the age of #[7]’) ou intangíveis (‘the relationship between money’), e fazer referência a lugares (‘all over the world’) ou a períodos de tempo específicos (‘ten years from now’).
Alguns exemplos das diferentes categorias funcionais são apresentados na Figura 2.
|
Posicionamento |
Organizadores discursivos |
Referência |
|
believe in Santa Claus |
if you are a |
is the one that |
|
I hope to be |
a lot of money |
|
|
they have to be |
the age of # |
|
|
should be reduced to |
on the other hand |
the relationship between money |
|
I will be working |
all over the world |
|
|
we can say that |
ten years from now |
Figura 2: Classificação funcional de feixes lexicais[8]
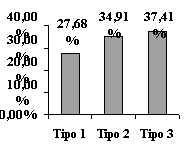
Em termos estruturais, o tipo mais freqüente é o que corresponde aos fragmentos de sintagmas nominais e/ou preposicionais como ‘a lot of money’, ‘the end of the’ e ‘on the other hand’, totalizando 37,41% das instâncias (cf. Figura 3).
Figura 3: Classificação estrutural
Os feixes que incorporam fragmentos de orações subordinadas (‘I hope to be’ e ‘we can say that’ sendo os dois exemplos mais comuns) correspondem a 34,91%. Por último, têm-se os feixes constituídos por fragmentos de sintagmas verbais (27,68%) como, por exemplo, ‘have a lot of’ (4º feixe mais freqüente) e ‘is the most important’ (7º feixe mais freqüente).
Com este resultado, observa-se que a escrita de alunos de cursos livres distancia-se dos registros escritos analisados por Biber, Conrad e Cortes (2004: 381-383). O registro ‘prosa acadêmica’ de usuários experientes caracteriza-se por não apresentar feixes que incorporem sintagmas verbais. No registro ‘livro didático’, esses feixes ocorrem com baixa freqüência assim como os feixes que incorporam fragmentos de orações subordinadas.
A classificação estrutural parece sugerir uma semelhança entre o corpus de pesquisa e um dos registros orais dos usuários experientes, ou seja, o registro ‘sala de aula’, já que os três tipos estruturais de feixes aparecem nos dados analisados e nesse registro com uma distribuição uniforme.
Com relação à classificação funcional, verifica-se que o tipo mais comum é o referencial com 67,83% das instâncias, incluindo feixes como ‘ten years from now’, ‘there are many people’ e ‘the relationship between money’. A Figura 4 resume a distribuição desses feixes:
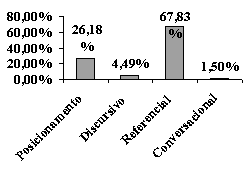
Figura 4: Classificação funcional
Seqüências como ‘will learn how to’, ‘we have to be’ e ‘we are going to’, ou seja, feixes de posicionamento, somam 26,18% sendo a segunda categoria mais freqüente.
Os feixes que organizam o discurso, explicitando as relações existentes no mesmo, aparecem em terceiro lugar, correspondendo a apenas 4,49% das instâncias. Os feixes discursivos mais freqüentes são ‘on the other hand’ na 8ª posição e ‘if you are a’ na 24ª posição.
O dado mais importante, no entanto, é a presença no corpus de feixes conversacionais com verbos discendi, do tipo ‘she told me that’ e ‘some people say that’. Tais construções são características do registro oral, mais especificamente, da fala reportada ou discurso indireto.
As classificações estrutural e funcional parecem sugerir para alguma forma de distanciamento da escrita dos aprendizes da escrita dos usuários experientes, e uma conseqüente aproximação da primeira ao registro oral dos usuários experientes.
Conclusões preliminares e encaminhamentos
Neste estudo fez-se um levantamento de feixes lexicais de quatro palavras em um corpus de redações de alunos de cursos livres de inglês, com o auxílio do programa Wordsmith Tools A classificação estrutural e funcional desses feixes foi feita de forma manual e com base nas categorias de Biber, Conrad e Cortes (2004).
Os resultados encontrados na escrita dos aprendizes investigados apontam para um estágio de interlíngua determinado. Ao escreverem em ILE, esse aprendizes se utilizam do principio idiomático, mas o fazem através de uma concentração de feixes do tipo 1 e de feixes de natureza conversacional. Isto os faz aproximar dos registros orais dos usuários experientes de inglês.
Caracterizar seguramente a utilização na escrita de feixes comumente associados com a fala, como um estágio de interlíngua, no entanto, requer mais estudos.
Como possível encaminhamento, os dados do presente trabalho devem ser contrastados com dados essencialmente orais, investigados da forma e com os instrumentos e métodos que foram utilizados aqui. O objetivo seria verificar até que ponto os aprendizes usam feixes semelhantes em sua fala. Um outro encaminhamento seria replicar o presente estudo com corpus formado de redações produzidas por aprendizes sabidamente em estágios superiores de interlíngua, talvez aqueles prestes a fazer os exames de proficiência das Universidades de Michigan e Cambridge.
Referências bibliográficas
AIJMER, K. Modality in advanced Swedish learners’ written interlanguage. In: GRANGER, S.; HUNG, J.; PETCH-TYSON, S. (Org.). Computer learner corpora, second language acquisition and foreign language teaching. Amsterdam: John Benjamins, 2002. p. 55-76.
ALTENBERG, B. Recurrent verb-complement constructions in the London-Lund corpus. In: AARTS, J.; DE HAAN, P.; OOSTDJIK, N. (Org.). English language corpora: analysis and exploitation. Amsterdam: Rodopi, 1993. p. 227-245.
BERBER SARDINHA, A. P. Lingüística de corpus. São Paulo: Manole, 2004.
BIBER, D; JOHANSSON, S.; LEECH, G.; CONRAD, S.; FINEGAN, E. Longman grammar of spoken and written English. London: Longman, 2000.
BIBER, D.; CONRAD, S.; CORTES, V. If you look at…: lexical bundles in university teaching and textbooks. Applied linguistics, v. 25, n. 3, p. 371-405, 2004.
CALOU, D; do NASCIMENTO, M.F. B. A posição do adjetivo no sintagma nominal: duas perspectivas de análise. Disponível em www.clul.ul.pt/equipa/ufrj_2002_nascimento_etal.pdf -. Acesso em: 19 set. 2005.
COWIE, A. P. (Org.). Phraseology: theory, analysis and applications. Oxford: Oxford University Press, 1998.
DE COCK, S.; GRANGER, S., LEECH, G.; MCENERY, T. An automated approach to the phrasicon of EFL learners. In: GRANGER, S. (Org.). Learner English on computer. London: Longman, 1998. p. 67-79.
GRANGER, S. The computer learner corpus: a versatile new source of data for SLA research. In: GRANGER, S. (Org.). Learner English on computer. London: Longman, 1998a. p. 3-18.
______. Prefabricated patterns in advanced EFL writing: collocations and formulae. In: COWIE, A. P. (Org.). Phraseology: theory, analysis and applications. Oxford: Oxford University Press, 1998b. p. 145-160.
______. (Ed.). Learner English on computer. London/New York: Longman, 1998c.
HYLAND, K. Teaching and researching: writing. Harlow: Longman, 2002.
LEECH, G. Preface. In: GRANGER, S. (Ed.). Learner English on computer. London/New York: Longman, 1998. p. xiv-xx.
HOUSEN, A. A corpus-based study of the L2-acquisition of the English verb system. In: GRANGER, S.; HUNG, J.; PETCH-TYSON, S. (Orgs). Computer learner corpora, second language acquisition and foreign language teaching. Amsterdam: John Benjamins, 2002. p. 77-116.
MOON, R. Frequencies and forms of phrasal lexemes in English. In: COWIE, A. P. (Org.). Phraseology: theory, analysis and applications. Oxford: Oxford University Press, 1998. p.79-100.
RENOUF, A.; SINCLAIR, J. Collocational frameworks in English. In: AIJMER, K.; ALTENBERG, B. (Orgs.). English corpus linguistics. London: Longman, 1991. pp. 128-143.
RINGBOM, H. Vocabulary frequencies in advanced learner English. In: GRANGER, S. (Ed.). Learner English on computer. London/New York: Longman, 1998. p. 41-52.
SCOTT, M. WordSmith tools, versão 3.0. Oxford: Oxford University Press, 1999.
SCOTT, M.; TRIBBLE, C. Textual patterns: keywords and corpus analysis in language education. Amsterdam: John Benjamins, 2006.
SINCLAIR, J. Corpus, concordance, collocation. Oxford: Oxford University Press, 1991.
______. Preface. In: LEWANDOWSKA-TOMASZCZYK, B. (Org.). Practical applications in language and computers. Frankfurt: Peter Lang, 2004. p. 7-11.
STUBBS, M. Words and phrases. Oxford: Blackwell, 2001.
VIANA, V. P. Feixes lexicais: avaliando a escrita em língua estrangeira. In: 15º InPLA – Linguagem: Desafios e Posicionamentos, 2005, São Paulo. Caderno de resumos. São Paulo, EMD Media Informática Ltda, 2005.
[1] Não há tradução oficial para idiom principle. Dinah Calou prefere, como muita adequação, o rótulo ´seleções combinatórias’.
[2] Scott e Tribble (2006: 131) afirmam que o conceito de agrupamento (cluster) adotado por eles, é “fundamentalmente o mesmo” que o conceito de feixe (bundle) adotado por Biber.
[3] Concordanciador é qualquer programa de computador que extrai itens lexicais de corpora e depois os centraliza em página ou na tela, permitindo leitura vertical do item propriamente dito e a verificação de ocorrências lexicais (fortuitas ou sistematizadas) à direita e à esquerda do mesmo.
[4] Tradução livre do seguinte fragmento: “Let us suppose that higher-education teacher X in a non-English speaking country teaches English to her students every week, and every so often sets them essays to write, or other written tasks in English. Now instead of returning those essays to students with comments and a sigh of relief, she stores the essays in her computer, and is gradually building up, week by week, a larger and more representative collection of her students’ work. Helped by computer tools such as a concordance package, she can extract data and frequency information from this ‘corpus’, and can analyse her students’ progress as a group in some depth. More significant are the research questions which open up once the corpus is in existence.”.
[5] Tradução livre do seguinte fragmento: “they offer an alternative means of differentiating between texts in different corpora”.
[6] Tradução livre do seguinte fragmento: “Three-word bundles can be considered as a kind of extender collocational association, and are thus extremely common. Four-word, five-word and six-word bundles are more phrasal in nature and correspondingly less common”.
[7] O símbolo utilizado (‘#’) refere-se a números de uma forma geral.
[8] A classificação funcional proposta por Biber, Conrad e Cortes (2004) apresenta subcategorias que, apesar de comentadas nesta seção, não se aplicam aos dados.